着陆器悬停任务
任务概述
着陆器悬停环境是基于 Gym 中月球着陆器环境的改进版本,将任务目标从着陆改为在月球表面悬停。该环境属于 Box2D 环境 系列。
| 项目 | 描述 |
|---|---|
| Action Space | Discrete(4) |
| Observation | Shape (4,) |
| Observation | High [1.5 1.5 5. 5.] |
| Observation | Low [-1.5 -1.5 -5. -5.] |
这是一个经典的火箭轨道优化问题。根据 Pontryagin 最大值原理,发动机完全打开或关闭是最优的动作选择策略。因此,动作空间被设计为离散的:发动机开启或关闭。悬停目标点固定位于坐标 (0,1)。状态向量的前两个维度表示坐标值,着陆器被设定为携带无限燃料。
着陆器从顶部中心位置开始,系统向其质心施加随机初始力,使着陆器获得随机初始速度。任务会在以下任一情况下终止:
- 着陆器坠毁:着陆器主体与月球表面发生接触
- 超出边界:着陆器离开有效窗口(x 轴坐标超出 [-1, 1] 范围)
- 时间限制:达到最大时间步长 400 步
- 系统休眠:着陆器进入休眠状态。根据 Box2D 定义,休眠的着陆器没有位移变化且不与其他物体产生碰撞:
- 当 Box2D 检测到物体处于静止状态时,会将其标记为休眠以降低计算资源开销
- 当清醒物体与休眠物体发生碰撞时,会唤醒休眠物体
动作空间
动作空间包含四个离散动作:
- 动作 0:不执行任何操作
- 动作 1:启动左引擎
- 动作 2:启动主引擎
- 动作 3:启动右引擎
观察空间
观察空间是一个 4 维向量,包含以下状态信息:
- 维度 0:着陆器的 X 轴坐标
- 维度 1:着陆器的 Y 轴坐标
- 维度 2:着陆器的 X 轴线速度
- 维度 3:着陆器的 Y 轴线速度
任务目标
悬停目标点位于坐标 (0,1)。当着陆器的 x 和 y 坐标偏差均小于 0.2 时,认为悬停成功并获得 10 分奖励;否则受到 0.3 分惩罚。
if abs(state[0]) <= 0.2 and abs(state[1]-1) <= 0.2:
reward = 10
else:
reward = -0.3训练流程
REVIVE 是一个基于历史数据的离线强化学习工具。在着陆器悬停任务上使用 REVIVE 的完整流程如下:
- 收集历史决策数据:收集着陆器悬停任务的历史运行数据
- 构建决策流图和训练数据:
- 结合业务场景和历史数据构建 决策流图
- 决策流图使用
.yaml文件描述业务数据的交互逻辑 - 训练数据使用
.npz或.h5文件存储决策流图中定义的节点数据
- 定义奖励函数:
- 根据任务目标设计 奖励函数
- 奖励函数指导控制策略优化,确保着陆器能够稳定悬停在目标位置
- 开始模型训练:
- 完成决策流图、训练数据和奖励函数定义后
- 使用 REVIVE 进行虚拟环境模型训练和策略模型训练
- 上线测试:
- 将训练好的策略模型部署到实际环境进行测试
收集历史数据
我们使用基于坐标信息的控制策略来模拟历史决策过程并收集训练数据。该策略根据着陆器当前位置与目标位置的偏差程度,生成相应的控制动作,引导着陆器尽可能接近目标位置。控制效果如下图所示:
定义决策流图和准备数据
完成历史数据收集后,需要根据业务场景构建决策流图和训练数据。决策流图准确描述了数据之间的因果关系。在着陆器悬停任务中,我们可以观察到着陆器的状态信息:4 维向量包含 X 轴坐标、Y 轴坐标、X 轴线速度和 Y 轴线速度。动作空间由四个离散动作构成:不执行操作、启动左引擎、启动主引擎和启动右引擎。
基于对业务逻辑的理解,我们构建了包含 3 个节点的决策流图:
obs节点:表示着陆器的当前状态action节点:表示着陆器的控制动作next_obs节点:表示着陆器下一时刻的状态
从 obs 到 action 的边表示动作仅由当前状态决定,从 obs 和 action 到 next_obs 的边表示下一时刻状态受当前状态和动作的共同影响。
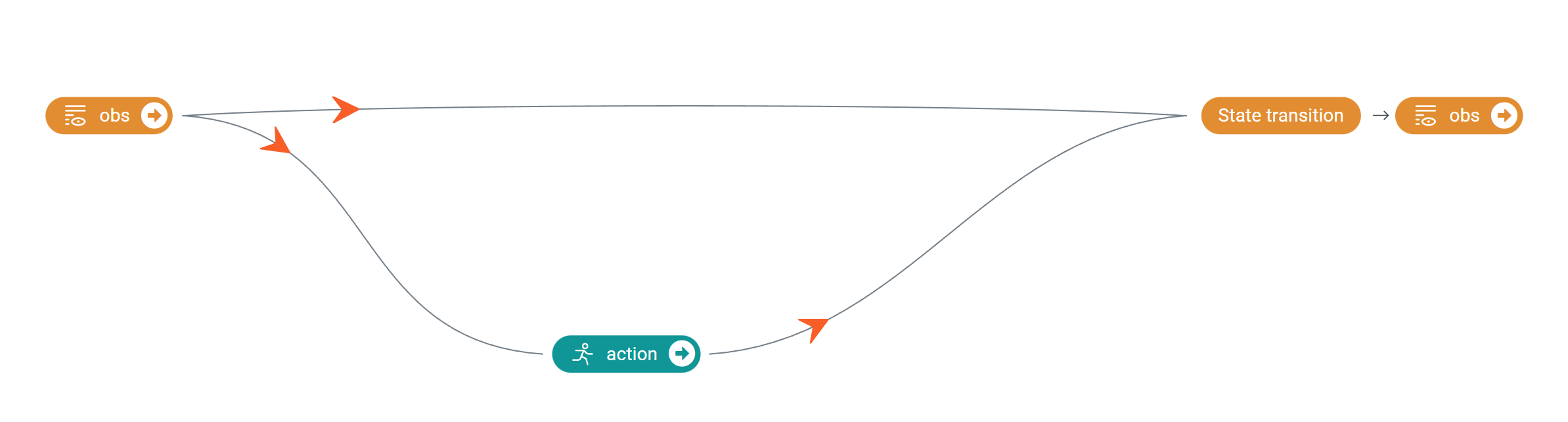
上述决策流图对应的 .yaml 配置文件如下:
metadata:
graph:
action:
- obs
next_obs:
- obs
- action
columns:
- obs_0:
dim: obs
type: continuous
- obs_1:
dim: obs
type: continuous
- obs_2:
dim: obs
type: continuous
- obs_3:
dim: obs
type: continuous
- action:
dim: action
type: category
values: [0, 1, 2, 3]在构建决策流图的过程中,我们将原始数据转换为 .npz 格式进行存储。
定义决策流图和准备数据的更多细节请参考 准备数据 章节。
定义奖励函数
奖励函数的设计对策略学习至关重要。良好的奖励函数能够有效指导策略向预期方向学习。REVIVE 支持以 Python 源文件的方式定义奖励函数。
悬停目标点位于坐标 (0,1)。当着陆器的 x 和 y 坐标偏差均小于 0.2 时,认为悬停成功并获得 10 分奖励;否则受到 0.3 分惩罚。下面展示了将着陆器悬停环境的任务目标转换为 REVIVE 所需的奖励函数。
import torch
from typing import Dict
def get_reward(data: Dict[str, torch.Tensor]):
"""
着陆器悬停任务奖励函数
Args:
data: 包含下一时刻观察的字典
Returns:
计算得到的奖励值
"""
return torch.where((torch.abs(data["next_obs"][...,0:1]) < 0.2) &
(torch.abs(data["next_obs"][...,1:2] - 1) < 0.2), 10, -0.3)定义奖励函数的更多细节请参考 定义奖励函数 章节。
训练控制策略
REVIVE 提供了完整的训练代码和数据集,详情请参考 REVIVE 源码库。完成 REVIVE 安装后,可以切换到 examples/task/LanderHover 目录下,运行以下命令进行虚拟环境模型训练和策略模型训练。训练过程中可以使用 TensorBoard 监控训练进度。训练完成后,您可以在 logs/<run_id> 目录下找到保存的模型文件(.pkl 或 .onnx 格式)。
python train.py \
-df data/LanderHover.npz \
-cf data/LanderHover.yaml \
-rf data/LanderHover.py \
-rcf data/config.json \
-vm once \
-pm once \
--revive_epoch 1000 \
--ppo_epoch 500 \
-run_id revive训练模型的更多细节请参考 训练模型 章节。
测试模型
训练完成后,可以使用 REVIVE SDK 提供的 Jupyter Notebook 脚本在着陆器悬停任务中进行策略控制效果测试。详情请参考 测试脚本。
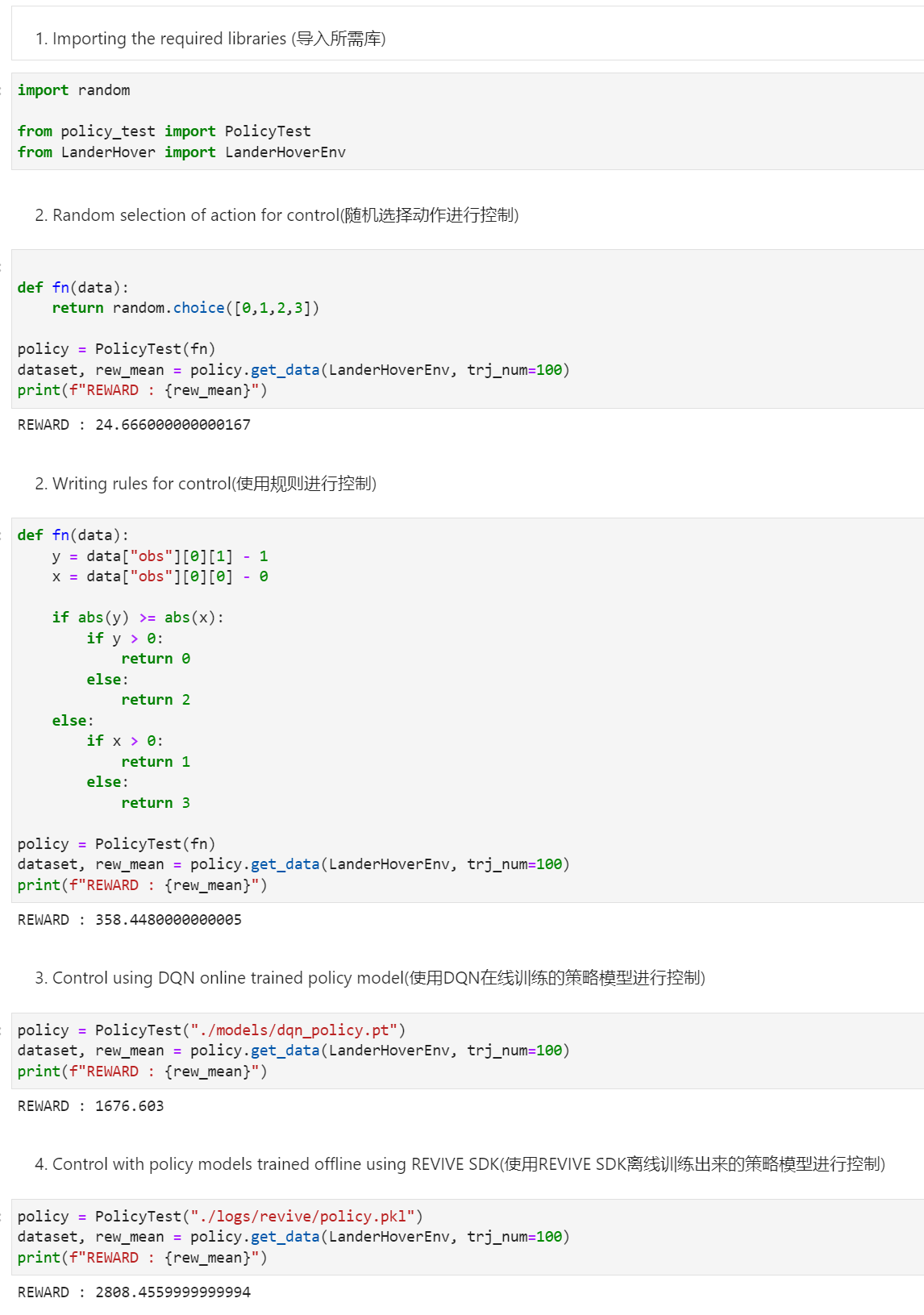
根据测试结果,用于采样数据的基于规则策略的轨迹奖励均值为 358,而使用 REVIVE 训练得到的控制策略的轨迹奖励均值达到 2808,策略控制效果提升显著。
不同策略的控制效果展示
下面动画展示了使用不同策略进行控制的效果对比。
策略1:随机选择动作进行控制
策略2:基于坐标信息的规则控制(采样数据所用策略)
策略3:使用 DQN 算法在线训练的策略进行控制
策略4:使用 REVIVE SDK 离线训练的策略进行控制