准备数据
在使用 REVIVE 之前,你首先需要构建好任务数据。决策流图、训练数据、奖励函数构成了一个完整的训练任务输入。 其中,奖励函数仅在需要训练策略模型时才是必须的。这一节我们会先讲解如何构建决策流图文件和训练数据文件。 用户也可以结合 任务示例 章节中的多种任务示例来进行训练任务的构建。
决策流图和训练数据是紧密耦合的,决策流图描述了各数据间的关系并定义了数据的不同类型,训练数据则包含了各节点数据:
- REVIVE 中使用
.yaml文件存储决策流图, 用于描述数据之间的关系或逻辑联系。 - REVIVE 中使用
.npz或.h5文件存储节点数据。
定义决策流图
使用 REVIVE 的最重要的一步是构建决策流图。决策流图是一个有向无环图,用于描述业务数据的交互逻辑。 决策流图中的每个节点都代表着不同的数据,每条边代表数据之间的映射关系。决策流图可以根据需要来扩展任意多个节点。 节点之间的顺序可以是任意指定的,单个节点可以作为多个节点的输入。 构建完成决策流图后,使用 .yaml 文件格式进行存储。
好的决策流图是 REVIVE 中不可或缺的一部分,并可以使得训练模型的过程更高效、预测结果更准确。
.yaml 文件主要包括两个属性 graph 和 columns。其中 graph 描述了数据中每个关键节点之间的关系。 columns 描述了数据的每个维度的属性。一般来说,我们应该在准备训练数据之前先结合任务场景定义一个决策流图。
| 属性 | 描述 |
|---|---|
| graph | 在真实环境中的决策流 |
| columns | 数据各特征纬度的描述 |
一个决策流图文件示例如下:
metadata:
graph:
action:
- obs
next_obs:
- obs
- action
columns:
- obs_1:
type : continuous
dim : obs
min : 0
max : 1
- obs_2:
type : discrete
dim : obs
max : 15
min : 0
num : 16
- action1:
type : category
dim : action
values : [0, 1, 3]
......
expert_functions:
next_obs:
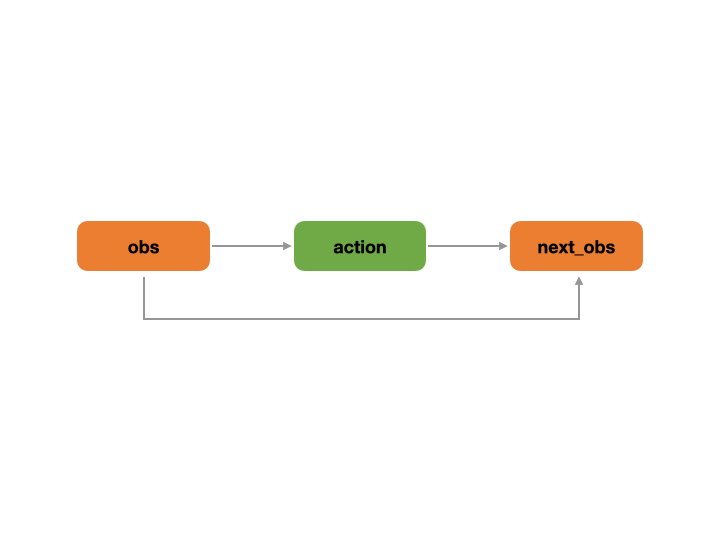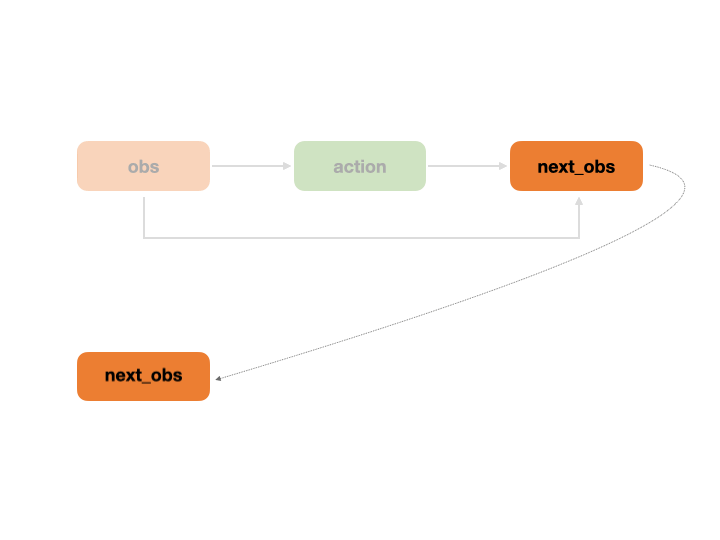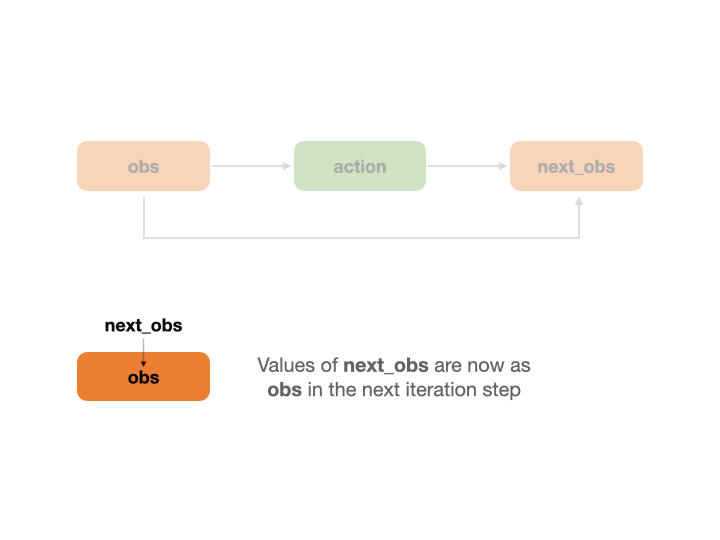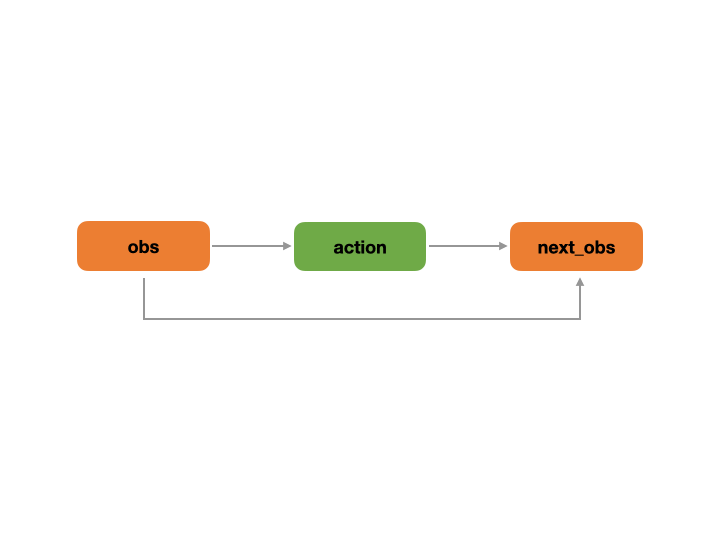
'node_function' : 'dynamics.transition'yaml 文件的第一部分(graph)描述了构建的决策流图。例如,在上面的 yaml 文件描述的决策流图中, graph 中有3个节点: obs , action 和 next_obs。 其中 obs 节点是 action 节点的输入,而 next_obs 节点的输入是 obs 节点和 action 节点。这种决策流程符合真实的业务逻辑: 一个智能体根据观察(obs)做出动作(action),环境转移根据当前状态(obs)和智能体的动作(action)做出相应的变化(即环境转移 next_obs)。
一个真实的任务案例是自动驾驶汽车。决策流图中的节点可以代表汽车的各个传感器,如摄像头、激光雷达、毫米波雷达,这些传感器会不断地获取车辆周围的信息, 并将这些信息传递给智能体。在这个案例中, obs 节点可以代表车辆周围的环境信息和车辆自身的状态信息,例如道路的宽度、长度、速度限制、交通标志和其他车辆的位置等等。 action 节点可以代表智能体根据观察做出的动作,例如加速、减速、转弯或者停车等。 next_obs 节点可以代表智能体完成动作后,后续新的车辆周围的环境信息和车辆自身的状态信息。 在进行决策时,智能体可能会根据当前的观察(obs 节点),计算出下一步的最佳行动方案(action 节点)。此时, next_obs 节点将包含新的环境信息和车辆自身的状态信息和行动方案,来预测行动实施后的下一步状态信息。因此, next_obs 节点的信息是由 obs 节点和 action 节点作为输入来共同作用得到的新状态结果,包含了车辆周围的新环境信息和车辆自身的新状态信息。
决策流图描述了智能体如何在真实环境中做出决策的过程。每个节点可以包含多个输入,意味着有多个节点变量影响该节点的输出。决策流图中的每个节点表示用于计算节点变量的决策过程, 边表示数据流。由于变量名称和决策关系是完全可变的,用户应该基于具体任务结合来构建符合业务逻辑的决策流图。
上述 yaml 文件对应的决策流图运行示例如下图所示。首先, obs 节点将数据输出到 action 节点,然后 next_obs 节点使用 obs 和 action 的数据来计算 next_obs 节点的值。
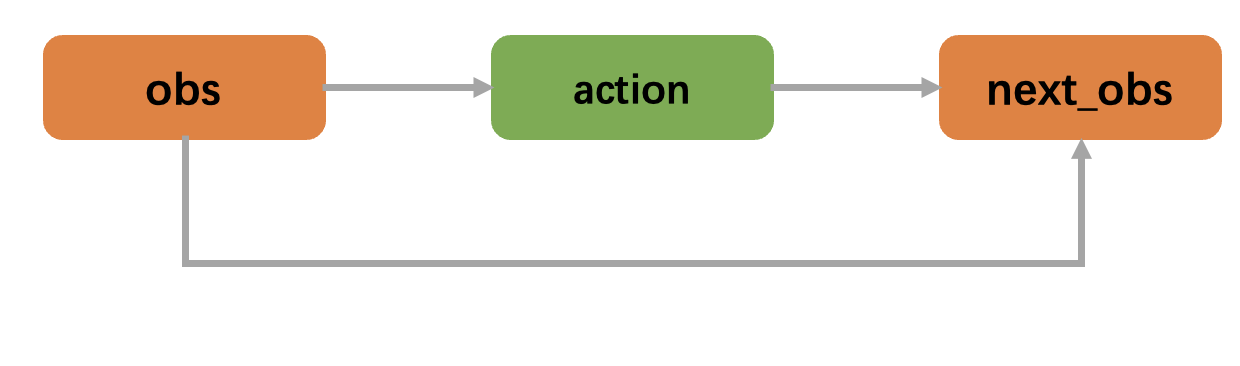
决策流图是一个循环调用的过程,它在多个时间步上运行。 在每个时间步中,决策流图会完整地运行一次。在这个过程中, next_* 节点会被视为转移节点, 对应的数据将作为下一个时间步的 * 节点输入使用。举例说明:t 时间步的 next_obs 节点数据会作为 t+1 时间步的 obs 节点数据。 以下动画展示了 REVIVE 是如何在时间步上进行决策流图的循环调用。
重要提示
用户在定义非转移节点时不应该使用 next_ 作为节点名前缀, 否则会引发解析冲突
一个决策流图中可以存在多个转移节点,例如下面的 yaml 决策流图中存在 next_o 和 next_s 两个转移节点。
graph:
a:
- o
- s
next_o:
- o
- a
next_s:
- o
- s
- a决策流图中的每个节点都可以定义多个节点作为输入以计算其自身的输出。
重要提示
决策流图是一个有向无环图(DAG),其中至少应包含一个转移节点。
yaml 文件的第二部分是以字典列表格式来描述数据的特征维度及其属性。你应定义节点数据的每一维特征的名称和属性。
每个字典的键表示特征维度的名称(例如,obs_1),dim 表示特征所属的节点名称(例如,obs 表示特征属于 obs 节点),type 表示特征数据的类型。
REVIVE 支持以下三种数据类型:
- continuous: 连续类型表明特征的值可以在连续实数空间中进行变化。例如,汽车速度就是一种连续特征值。用户还可以提供
max和min参数来指定数值范围。如果用户未提供数值范围,则将自动从训练数据中计算得到的最小值和最大值来进行自动范围设置。 - discrete: 离散类型表明特征值只能从一组离散的实数中选择,这些数值在给定范围内具有相等的间隔。例如,年龄可以被离散化为若干个年龄段(例如 20-29 岁、30-39 岁等)。在这种情况下离散集合可以是
{20, 30, 40}。max和min参数指定数值范围(它们将包含在离散集合中);如果用户未提供数值范围,则将自动从训练数据中抽取最小值和最大值进行设置。用户需要指定num参数来限制离散化的数量。在上述决策流示例中,obs的第二维度的有效值为[0, 1, 2, …, 15]。 - category: 类别数据表明特征的值只能取有限的整数子集,并且子集中的数字之间没有数值关系。例如,考虑一个人的职业类型,它可能属于医生、教师、工程师等多种职业之一。该数据类型可以视为分类。用户需要指定相应的参数来描述每个类别对应的值。在上述决策流示例中,
action的有效值为[0, 1, 3]。
重要提示
REVIVE 不支持字符串格式的数据类型。
在 *.yaml 文件中,我们也可以插入 expert_function 以导入专家函数,利用专家知识来替代神经网络的学习。正确使用专家函数可以降低任务难度,提高模型训练效果。
具体可以参考 高级工具 部分。
重要提示
默认情况下,决策流图的第一个节点会被选作目标策略节点(即训练策略时所要优化的节点)。我们也可以配置 -tpn 参数以指定其他节点作为策略节点。更多细节请参考 训练模型。
构建数组数据
训练数据
通过 .yaml 文件完成决策流图的定义后,用户应根据决策流图将历史数据构建为对应的数组数据。数据应以 Python 字典的形式组织,以节点名称作为键(key),以 Numpy 数组作为值(value)。
所有值均为二维 ndarray,其中样本数 N 为第一维度,特征数 C 为第二维度。键名应与 .yaml 文件中 graph 描述的节点名称对应。index 是一个额外的数据,用以标记数据中每条轨迹的结束索引。例如,如果数据的形状为 (100, F) 并包含两个轨迹,其长度分别为 40 和 60,则 index 应设置为形如 [40, 100] 的 np.ndarray。
当数据以字典形式构建完成后,需将它们存储在单个 .npz 或 .h5 文件中。(.npz 文件可通过 numpy.savez_compressed 函数保存,而 .h5 文件可使用 revive.utils.common_utils.save_h5 函数保存)。
import numpy as np
from revive.utils.common_utils import save_h5
data = { "obs": obs_array, "act": act_array, "index": index_array }
# 保存 npz 文件
np.savez_compressed("data.npz", **data)
# 保存 h5 文件
save_h5("data.h5", data)验证数据(可选项)
此外,我们可以提供另一个数据文件作为验证数据集。该数据集应具有与训练文件相同的数据结构,这意味着这两个文件可以用同一个 .yaml 文件来描述。
如果未提供此数据,REVIVE 将自动将训练数据按 1:1 的比例分成两部分,分别作为训练数据集和验证数据集。我们可以修改配置文件中的相关参数,以控制数据拆分的比例和方法。
本节介绍了如何构建 REVIVE 可使用的数据集,主要包括构建决策流图和描述数据特征维度及其属性。决策流图是一个有向无环图,表示业务数据之间的交互逻辑,可以根据任务需要自由扩展。 构建完成的决策流图和数组数据应该分别存在在 .yaml 文件和 .npz 文件中。 在任务案例章节,REVIVE 提供了一些可运行的案例,包括已经准备好的决策流图和数组数据,您可以参考案例的数据加深理解。