四足机器人控制任务
任务介绍

HalfCheetah 是传统强化学习中一个经典的控制问题。关于这个任务的详细描述可以在Mujoco-HalfCheetah这里找到。 D4RL是一个经典的离线强化学习数据集,在这个例子中我们将采用其中的halfcheetah-medium-v2 数据集作为例子来进行 REVIVE 训练。下面将介绍如何通过 REVIVE 在 halfcheetah-medium-v2数据集上训练得到一个理想的环境与策略。最后,我们将对比数据集中的原始策略与 REVIVE 得到的策略,来直观展示 REVIVE 的强大能力。
| 项目 | 描述 |
|---|---|
| Action Space | Continuous(6,) |
| Observation | Shape (17,) |
| Observation | High [inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf] |
| Observation | Low [-inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf] |
动作空间
动作空间由连续的 6 维向量组成,分别表示控制各关节的力矩。每个维度的取值范围为 [-1, 1]。
观察空间
状态是一个 17 维向量,包括各关节的角度,角速度,以及机器人在
初始状态
机器人从原点开始,从初始状态准备向前奔跑。
任务结束
机器人跑完 1000 步后任务会被强制结束。
任务目标
机器人的目标是在固定的步数内,尽可能多地往前跑,同时保持自身能量消耗较小。这点在奖励函数的定义中得以体现。
训练模型
REVIVE是一个历史数据驱动的工具。根据文档教程部分的描述,在冰箱温控任务上使用REVIVE可以分为以下几步:
- 收集历史决策数据:收集冰箱温控任务的历史决策数据。
- 构建决策流图和数组数据:
- 结合业务场景和收集的历史数据构建 决策流图和数组数据。
- 决策流图主要描述业务数据的交互逻辑,使用
.yaml文件存储。 - 数组数据存储决策流图中定义的节点数据,使用
.npz或.h5文件存储。
- 定义奖励函数:
- 为了获得更优的控制策略,需要根据任务目标定义奖励函数。
- 奖励函数定义了策略的优化目标,可以指导控制策略将冰箱内温度更好地控制在理想温度附近。
- 开始模型训练:
- 定义完决策流图、训练数据和奖励函数后,可以使用REVIVE开始虚拟环境模型训练和策略模型训练。
- 上线测试:
- 将REVIVE训练的策略模型进行上线测试。
准备数据
这里我们不需要手动收集历史数据,因为 D4RL 库已经提供标准的离线历史数据。首先,我们需要下载并预处理 D4RL 数据集,使得它符合 REVIVE 的输入形式。 数据处理脚本在 data/generate_data.py,我们可以进入 data 目录,运行以下命令得到处理后的数据集。
python generate_data.py处理过程中有几点需要注意:
- 轨迹切分:正如
准备数据 <../tutorial/data_preparation_cn>{.interpreted-text role="doc"} 提到的,REVIVE 的数据集字段中要求有index信息,而这一项需要我们从 halfcheetah-medium-v2 数据集中构建。 具体方法为:我们根据数据集中 t+1 时刻的obs是否与 t 时刻的next_obs一致,来切分轨迹,并生成index信息。 - 还原
delta_x信息:由于 halfcheetah-medium-v2 数据集并不直接提供 x 坐标信息,而在 HalfCeetah 任务中,x 坐标信息对于计算reward尤为关键。因此,我们通过数据集中的reward信息来还原delta_x信息。这里:
处理细节用户可以参考 data/generate_data.py。
这样我们就得到了 .npz 文件,我们将它放入 data/ 文件夹中。
定义决策流图
下面的示例显示 .yaml 中的详细信息。通常,有两部分信息构成 .yaml 文件,分别是 graph 和 columns 。 其中 graph 部分定义了决策流图。columns部分定义了数据的组成。具体请参考文档:准备数据 <../tutorial/data_preparation_cn> 。 请注意,由于 obs 存在 17 个维度, obs 的列应该 按顺序 定义在 columns 部分。 如Mujoco-HalfCheetah 所示, 状态和动作中的变量是 连续 的,我们使用 continuous 来描述每一列数据。
另外,注意这里我们对 delta_x 定义了 min, max 范围 [-1, 1]。 这是因为在 policy 训练时,每一步的 delta_x 可能会超越数据集的范围(数据集中 delta_x 约在 [-0.12, 0.43])。 这对 REVIVE 中 数据归一化 处理有很大影响。 默认情况 REVIVE 将读取数据中的 min, max 值作归一化。
metadata:
columns:
- obs_0:
dim: obs
type: continuous
- obs_1:
dim: obs
type: continuous
...
- obs_16:
dim: obs
type: continuous
- action_0:
dim: action
type: continuous
- action_1:
dim: action
type: continuous
...
- action_5:
dim: action
type: continuous
- delta_x:
dim: delta_x
type: continuous
min: -1
max: 1
graph:
action:
- obs
delta_x:
- obs
- action
next_obs:
- obs
- action
- delta_x这样我们就得到了 .yaml 文件,我们也将它放入 data/ 文件夹中。
构建奖励函数
这里我们可以使用 Mujoco 中对 HalfCheetah 定义的奖励函数,详情参考 HalfCheetah-Env
import torch
import numpy as np
from typing import Dict
def get_reward(data : Dict[str, torch.Tensor]) -> torch.Tensor:
action = data["action"]
delta_x = data["delta_x"]
forward_reward_weight = 1.0
ctrl_cost_weight = 0.1
dt = 0.05
if isinstance(action, np.ndarray):
array_type = np
ctrl_cost = ctrl_cost_weight * array_type.sum(array_type.square(action),axis=-1, keepdims=True)
else:
array_type = torch
# ctrl_cost 代表做 action 的体能开销,由 action 的二范数平方构成
ctrl_cost = ctrl_cost_weight * array_type.sum(array_type.square(action),axis=-1, keepdim=True)
x_velocity = delta_x / dt
# forward_reward 代表 halfcheetah 向前运动的奖励,x_velocity 越大,奖励值越高
forward_reward = forward_reward_weight * x_velocity
# 最终 halfcheetah 得到的 reward 由 forward_reward,ctrl_cost 构成
# 这也对应了 halfcheetah 任务的目标:在固定的步数内,halfcheetah 需要尽可能多地往前跑,同时保持自身能量消耗较小
reward = forward_reward - ctrl_cost
return reward这样我们就得到了奖励函数文件,我们也将它放入 data/ 文件夹中。
使用REVIVE SDK训练控制策略
现在,我们已经构建完成运行 REVIVE SDK 所需的文件, 包括 .npz 数据文件, .yaml 文件和 reward.py 奖励函数。 还有另一个文件 config.json,该文件保存了训练所需的超参数。这四个文件位于 data/ 文件夹中。 现在我们的文件目录如下所示:
|-- data
| |-- config.json
| |-- generate_data.py
| |-- halfcheetah_medium-v2.hdf5
| |-- halfcheetah-medium-v2.npz
| |-- halfcheetah-medium-v2.yaml
| `-- halfcheetah_reward.py
`-- train.py
用户可以切换到 examples/task/HalfCheetah 目录下,运行下面的 python 命令开启虚拟环境模型训练和策略模型训练。在训练过程中,我们可以随时使用tensorboard打开日志目录以监控训练过程。
python train.py \
-df data/halfcheetah-medium-v2.npz \
-cf data/halfcheetah-medium-v2.yaml \
-rf data/halfcheetah_reward.py \
-rcf data/config.json \
--target_policy_name action \
-vm once \
-pm once \
--run_id halfcheetah-medium-v2-revive \
--revive_epoch 1500 \
--sac_epoch 1500重要提示
REVIVE SDK已经提供了训练所需的数据和代码,详情请参考 REVIVE SDK源码库。
测试模型
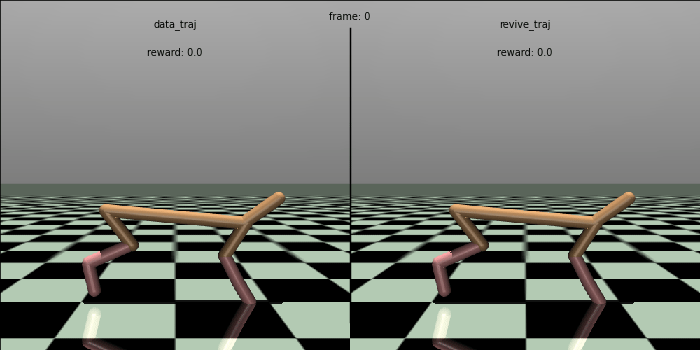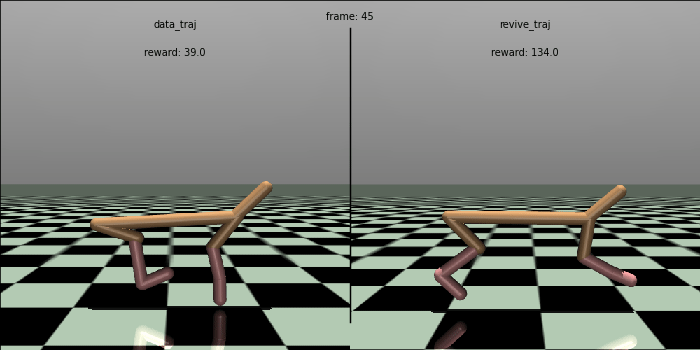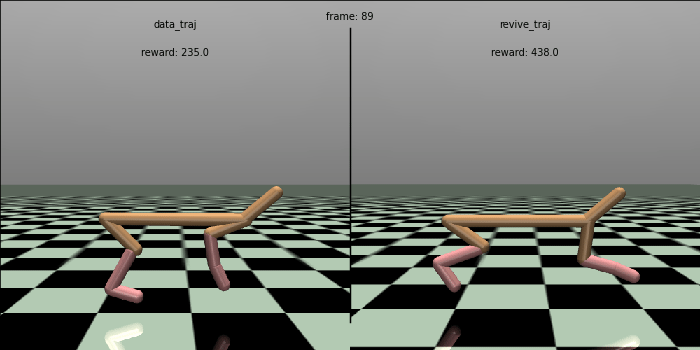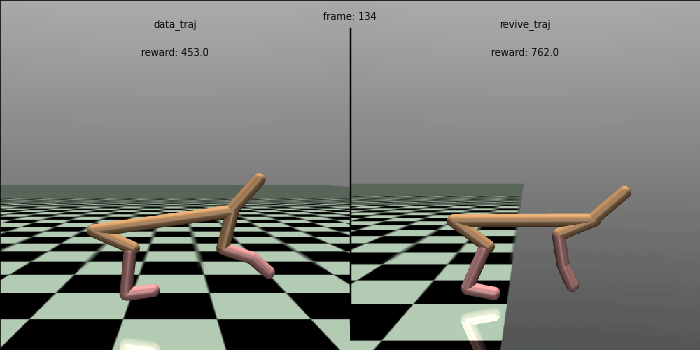
当REVIVE完成虚拟环境模型训练和策略模型训练后, 我们可以在日志文件夹(logs/<run_id>)下找到保存的模型( .pkl 或 .onnx)。我们尝试在真实环境上测试策略的效果,并和数据中的控制效果进行对比。在下面的测试代码中, 我们将策略在真实环境中跑 100 轮,每轮执行 1000步,输出这100次总的平均回报(累计奖励)。 REVIVE SDK 的策略获得了 7156.0平均奖励,远高于数据中策略的 4770.3 奖励值,控制效果提高了约 50%。
import pickle
import d4rl
import gym
import numpy as np
def take_revive_action(state):
new_data = {}
new_data['obs'] = state
action = policy_revive.infer(new_data)
return action
policy_revive = pickle.load(open('policy.pkl', 'rb'))
env = gym.make('halfcheetah-medium-v2')
re_list = []
for traj in range(100):
state = env.reset()
obs = state
re_turn = []
done = False
while not done:
action = take_revive_action(obs)
next_state, reward, done, _ = env.step(action)
obs = next_state
re_turn.append(reward)
print(np.sum(np.array(re_turn)[:]))
re_list.append(np.sum(re_turn))
print('mean return:',np.mean(re_list), ' std:',np.std(re_list), 、
' normal_score:', env.get_normalized_score(np.mean(re_list)) )
# REVIVE平均回报:
# mean return: 7155.900144836804 std: 63.78200350280033 normal_score: 0.5989506173038248为了更直观地比较策略,我们生成策略的控制对比动画。可以发现,REVIVE的策略可以控制 HalfCheetah 跑得更快更稳定, 比数据中的原始策略更加优秀。